Projects
My current research and project mainly lies in the following two aspects: Theoretical foundation of deep/machine learning and Efficient learning algorithm.
Theoretical foundation of deep/machine learning
Deep learning explanation, convergence, and generalization analysis
Graph neural network learning theory
Fairness in deep/machine learning
Deep reinforcement learning theory
Matrix completion
Efficient learning algorithm
Neural network compression
Data compression
Efficient neural network architectures
Few-shot learning
Distributed machine learning
Foundation model
Research highlights
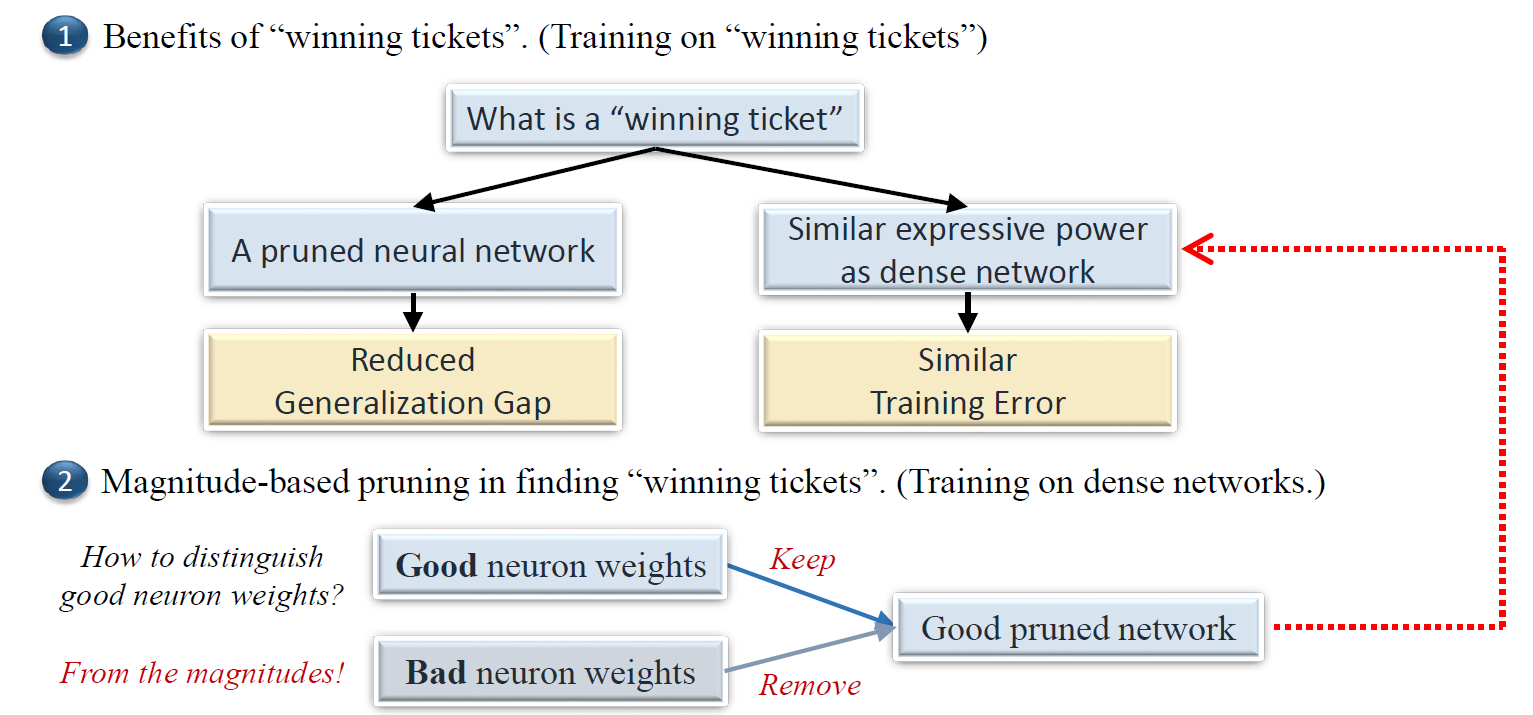
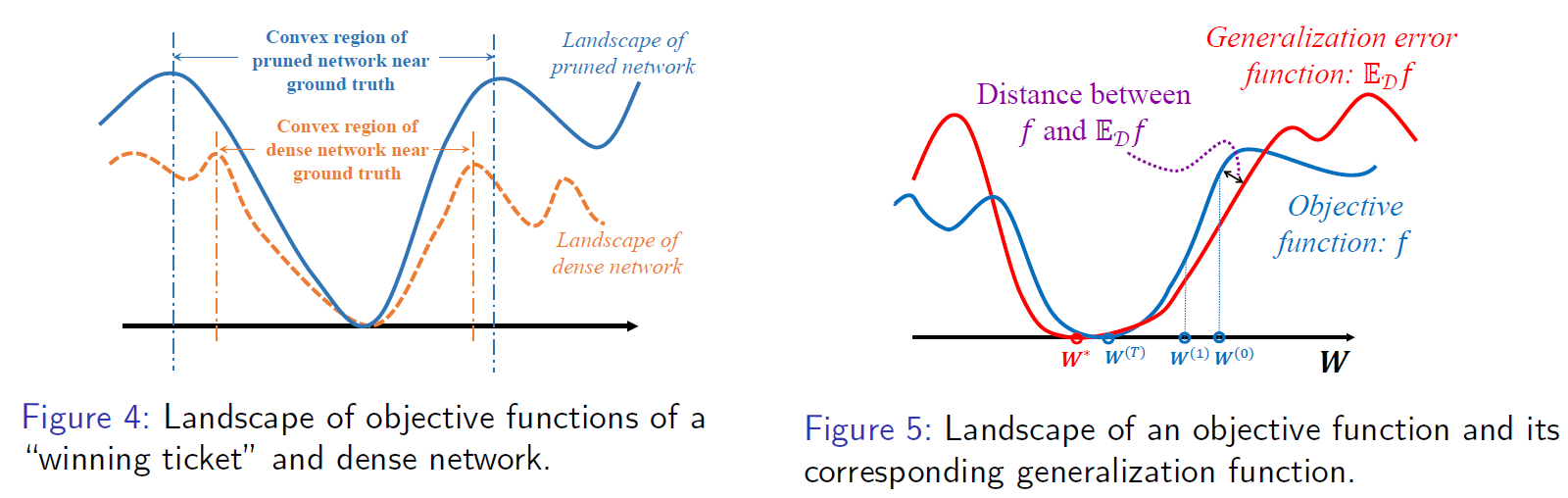
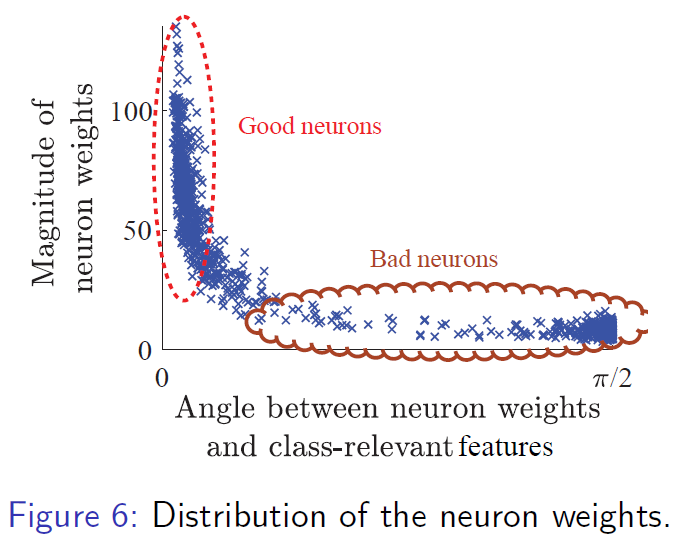
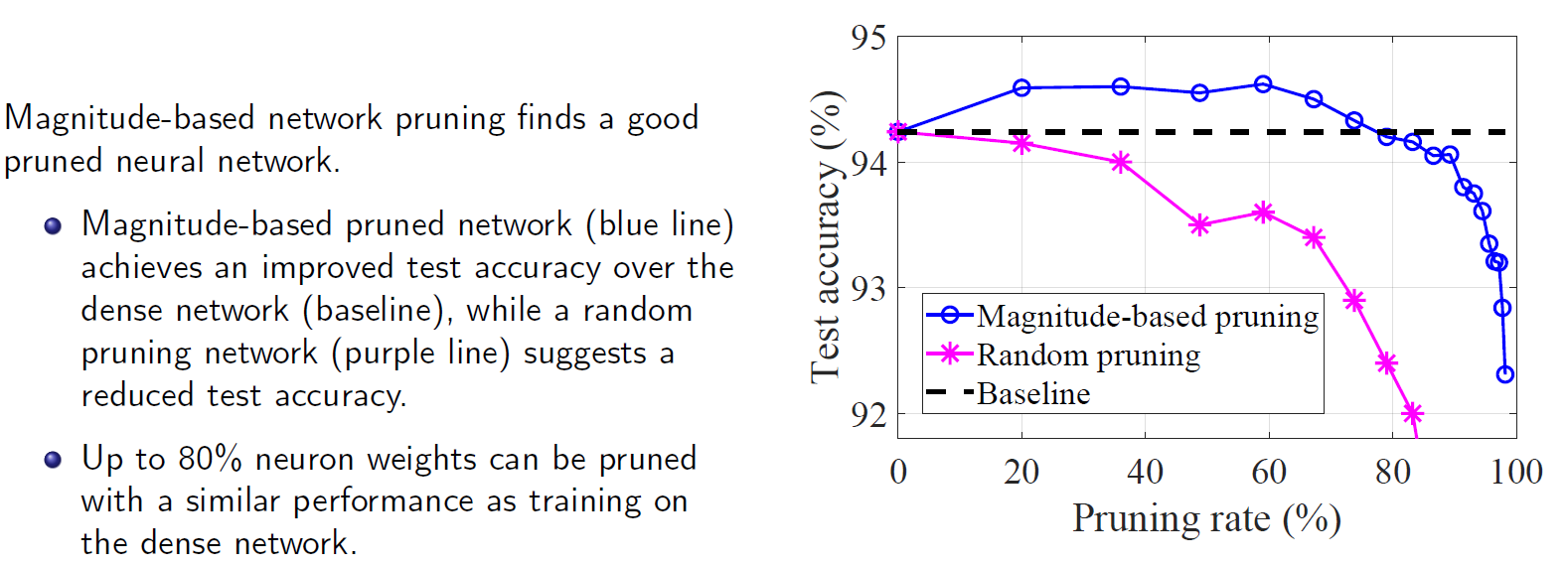
Neural network pruning [slides]
Discription: Neural network pruning is a technique used to reduce the size of a neural network by removing unnecessary connections and neurons while maintaining or improving its performance. This technique can help to make the network more sparse, leading to several advantages such as decreased computational cost, memory usage, energy consumption, and carbon footprint. Furthermore, recent numerical findings have indicated that a well-pruned neural network can exhibit improved test accuracy and faster convergence rates. This type of pruned network is commonly referred to as "winning tickets" within the context of the lottery ticket hypothesis (LTH), and numerical evidence suggests that magnitude-based pruning is effective in finding such "winning tickets". However, LTH and its relevant paper cannot explain the benefits of training the "winning tickets" and why using magnitude-based pruning approach can find the "winning tickets".
Shuai Zhang, Meng Wang, Pin-Yu Chen, Sijia Liu, Songtao Lu, Miao Liu. “Joint Edge-Model Sparse Learning is Provably Efficient for Graph Neural Networks.” In International Conference on Learning Representations (ICLR), 2023. [pdf]
Shuai Zhang, Meng Wang, Sijia Liu, Pin-Yu Chen, and Jinjun Xiong. “Why Lottery Ticket Wins? A Theoretical Perspective of Sample Complexity on Sparse Neural Networks.” In Proc. of the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS), 2021. [pdf]
Self-training via unlabeled data (semi-supervised learning) [slides]
Discription: Self-training is a type of semi-supervised learning approaches that combines labeled and unlabeled data to improve the accuracy of a model. It is useful in situations where obtaining labeled data is expensive or time-consuming, but there is an abundance of unlabeled data available. In many real-world scenarios, labeled data can be scarce or difficult to obtain, e.g., medical images, and labeling large datasets can be expensive or time-consuming, e.g., labeling ImageNet took almost 4 years with 49,000 workers from 167 countries. Most importantly, by incorporating unlabeled data, self-training can improve the accuracy of a model beyond what is possible with purely labeled data. Despite the use of self-training and deep learning in various studies, there is currently a lack of theoretical understanding regarding their integration and performance. In addition, certain numerical experiments have indicated that the non-linear characteristics of neural networks could result in a decline in performance when utilizing self-training. To address the disparity between numerical results and theoretical comprehension of self-training, we present a convergence analysis of the self-training algorithm, along with theoretical guidelines for selecting hyperparameters to ensure improved generalization using unlabeled data. Our specific contributions include
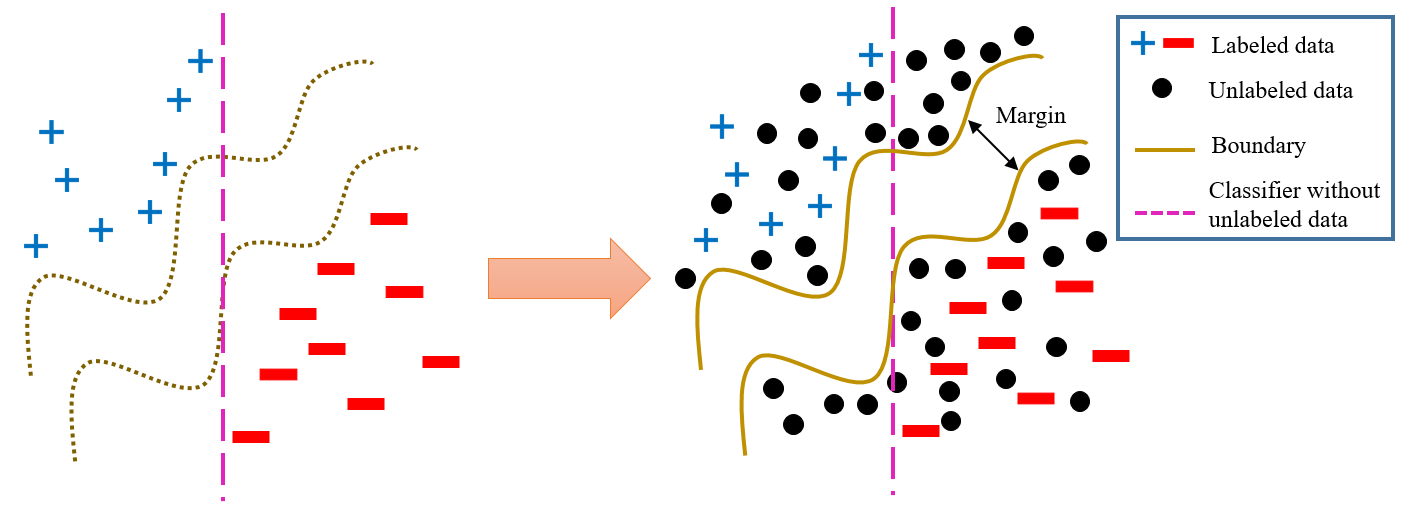
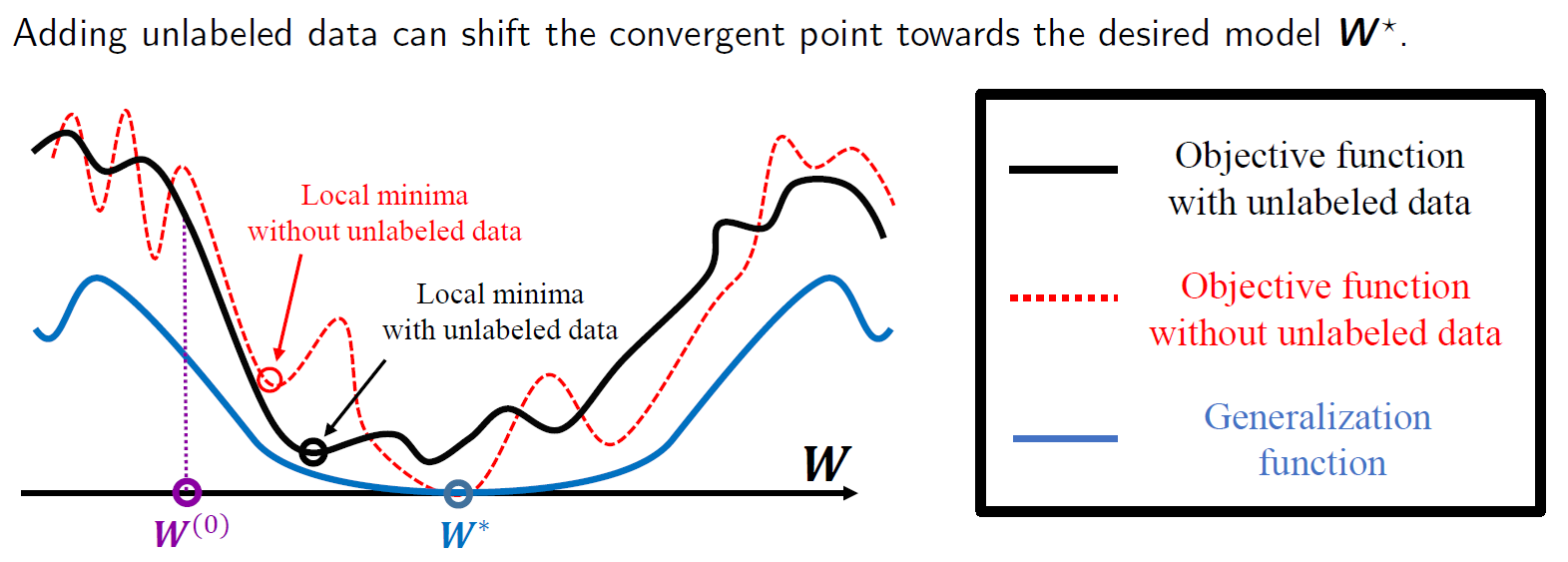
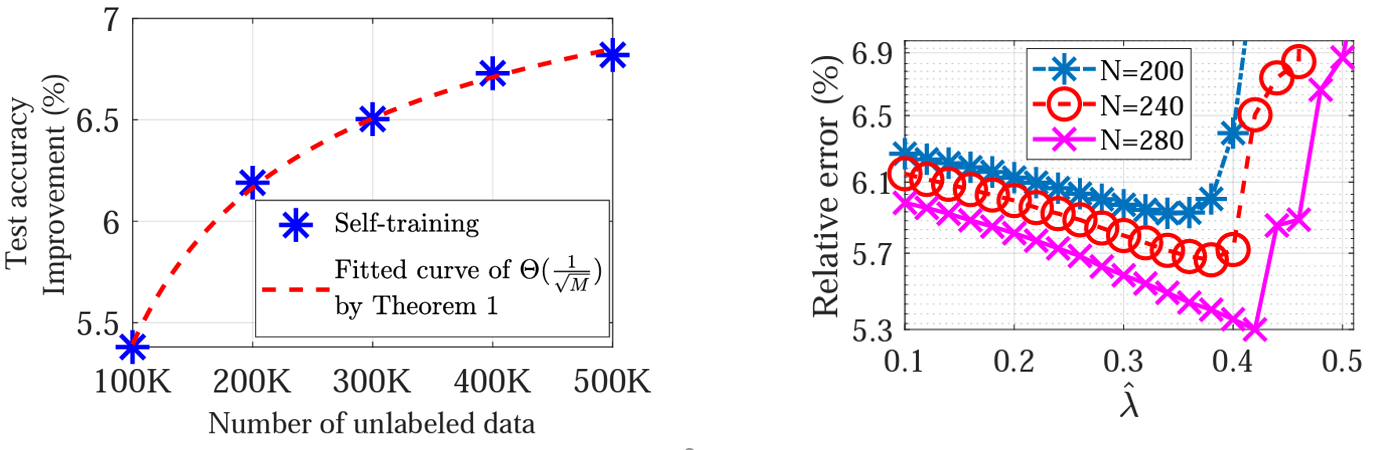

Shuai Zhang, Meng Wang, Sijia Liu, Pin-Yu Chen, and Jinjun Xiong. “How unlabeled data improve generalization in self-training? A one-hidden-layer theoretical analysis.” In Proc. of The Tenth International Conference on Learning Representations (ICLR), 2022. [pdf]
Graph Neural Networks [slides]
Discription: Graph neural networks (GNNs) are a class of deep learning models that are designed for data learning with graph structured data. Examples of data that can be represented as graphs include social networks, biological networks, recommendation systems, communication networks, Internet of Things (IoTs) networks, and transporation networks.
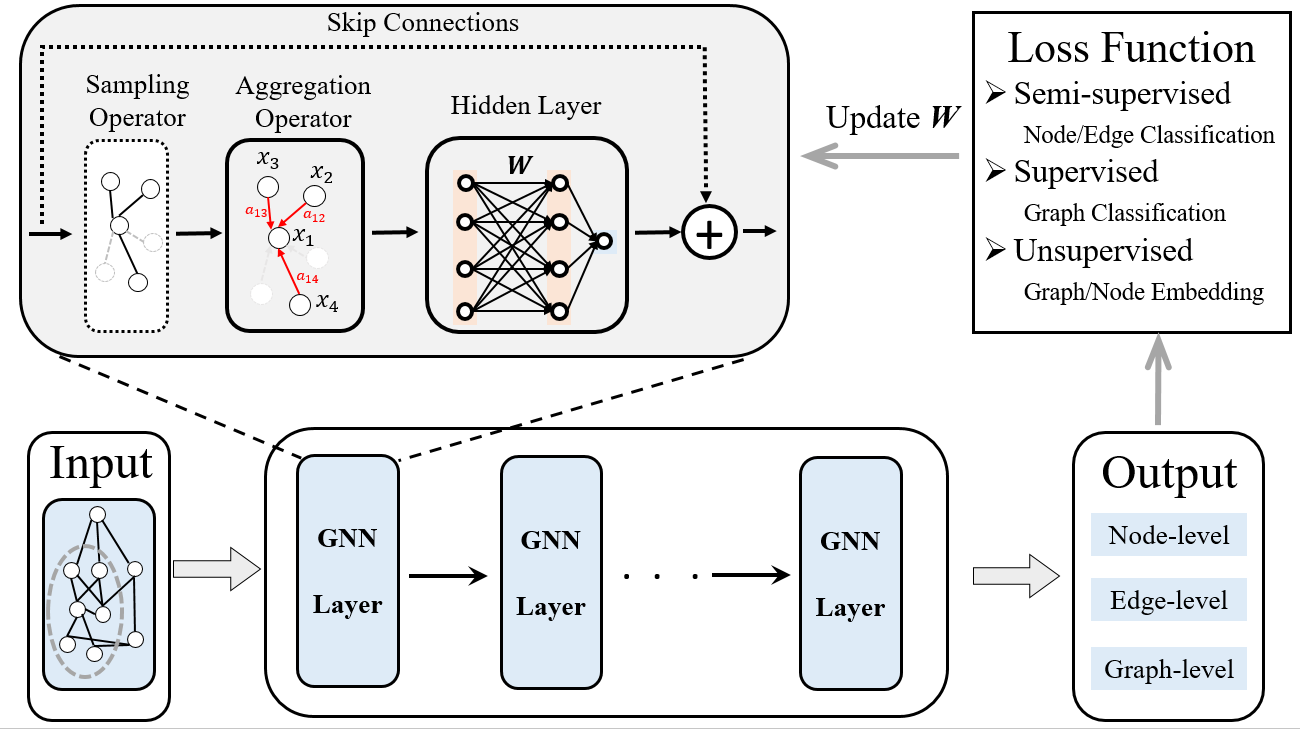
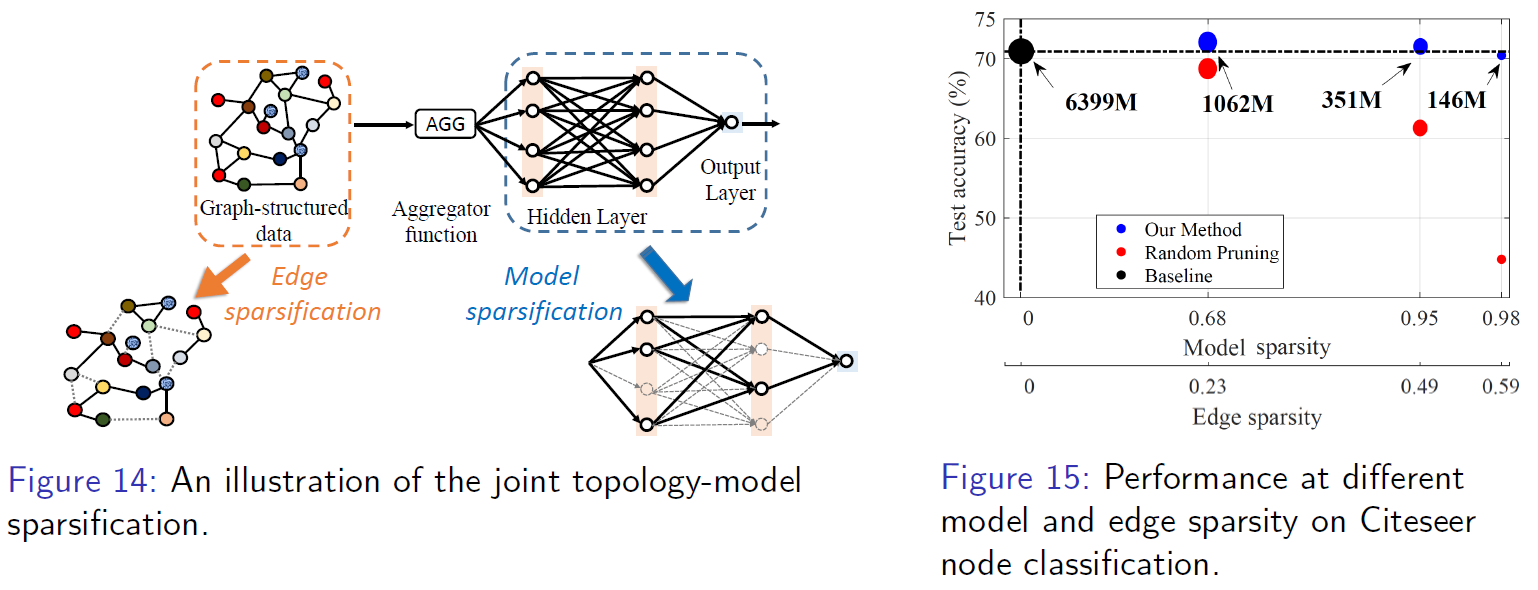
Shuai Zhang, Meng Wang, Pin-Yu Chen, Sijia Liu, Songtao Lu, Miao Liu. “Joint Edge-Model Sparse Learning is Provably Efficient for Graph Neural Networks.” In International Conference on Learning Representations (ICLR), 2023. [pdf]
Shuai Zhang, Meng Wang, Sijia Liu, Pin-Yu Chen, and Jinjun Xiong. “Fast Learning of Graph Neural Networks with Guaranteed Generalizability: One hidden-layer Case.” In Proc. of 2020 International Conference on Machine Learning (ICML), pp. 11268-11277. PMLR, 2020. [pdf]
Low-rank Hankel Matrix Completion [slides]
Discription: Given given partially observed data, we need to recover original data by filling in missing entries and removing outliers. This problem is common in various fields such as recommendation systems, computer vision, and signal processing. To illustrate, imagine a data matrix representing the renewable energy output of multiple solar arrays over time. The time-series data for each array may be affected by a few shared factors, like temperature, wind speed, and UV index. As there are more data points than factors, it suggests that the data matrix is low-rank. Being able to fill in missing data or predict future outputs is crucial for energy systems planning and control. However, existing algorithms require at least one observation in each column, making it unfeasible to apply them in practical scenarios where all data is lost or inaccessible, such as prediction tasks. To solve this issue, we utilize the Hankel matrix to capture the temporal correlation across the data. We propose non-convex algorithms by exploring the structured Hankel matrix, and the algorithms achieve reduced sample complexity and less computational time with theoretical guarantees. Our specific contributions include
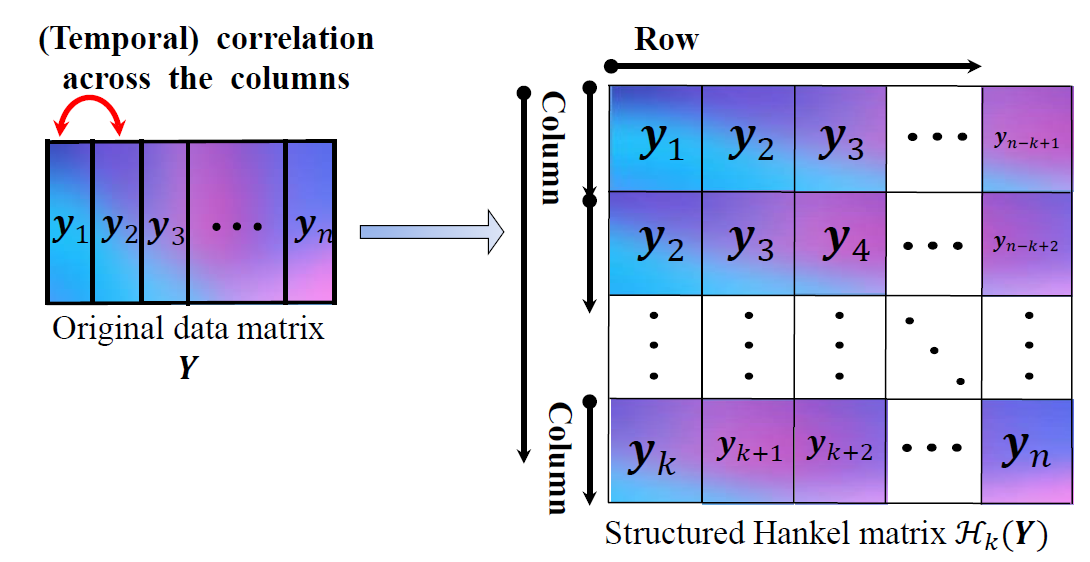
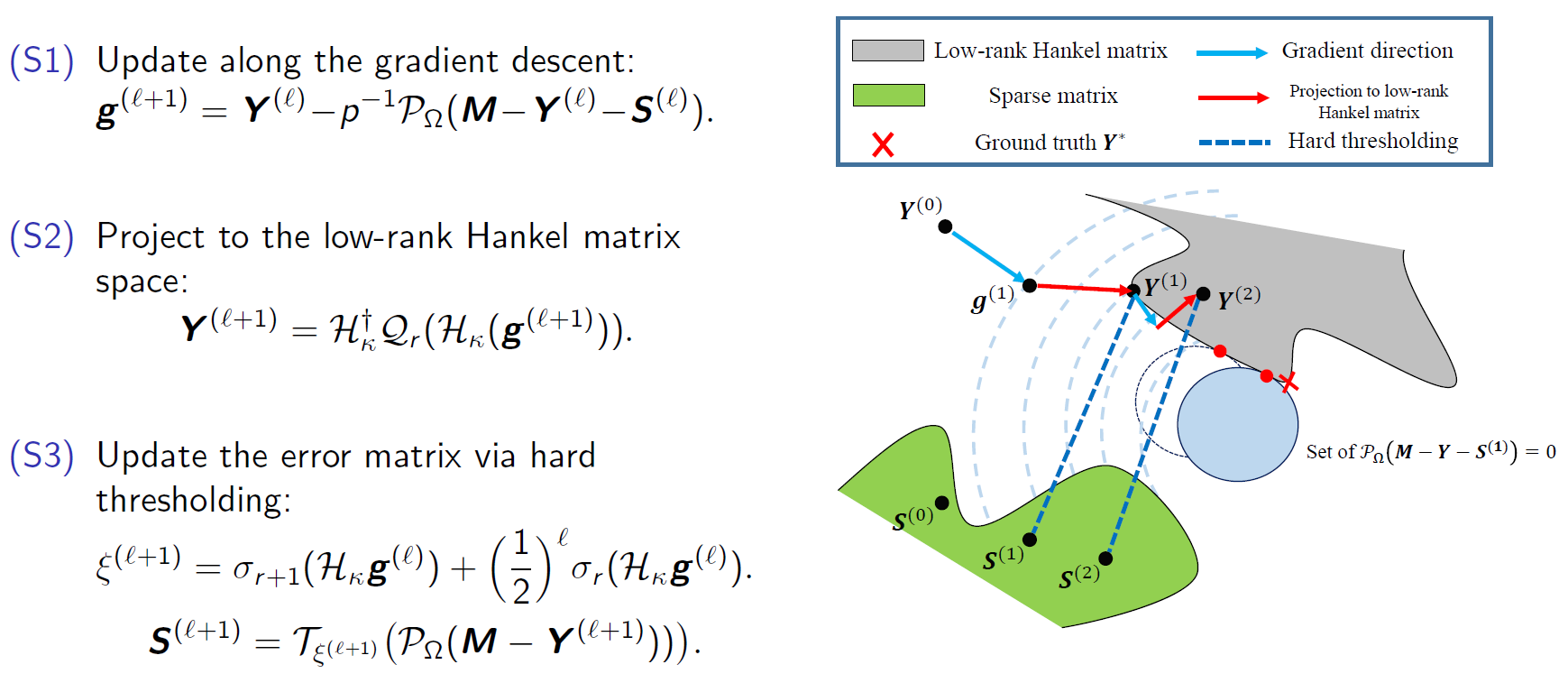
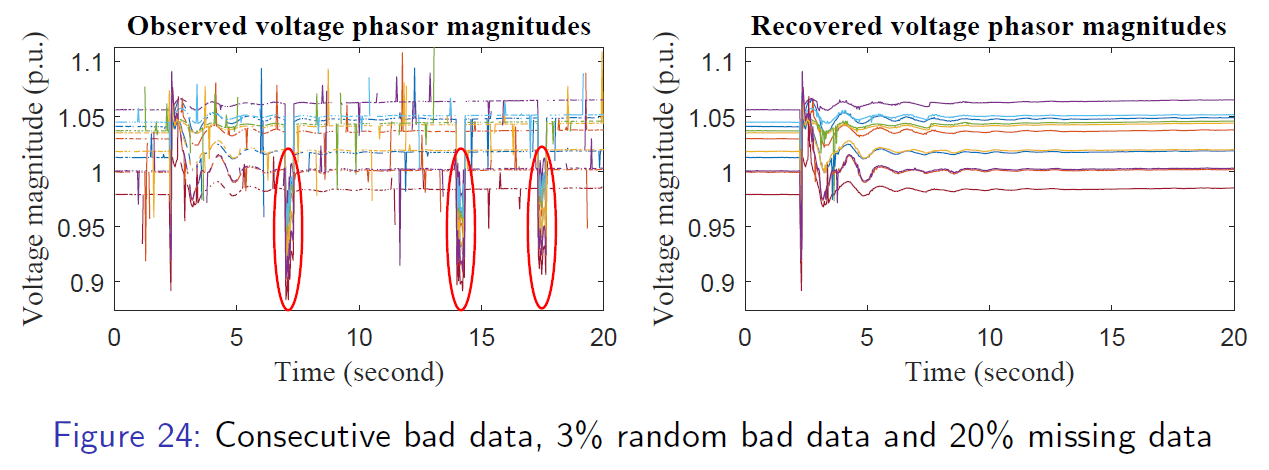
Shuai Zhang, Meng Wang, Sijia Liu, Pin-Yu Chen, and Jinjun Xiong. Shuai Zhang, and Meng Wang. “Correction of corrupted columns through fast robust Hankel matrix completion.” IEEE Transactions on Signal Processing (TSP), no. 10: 2580-2594. IEEE, 2019. [pdf]
Shuai Zhang, Yingshuai Hao, Meng Wang, and Joe H. Chow. “Multichannel Hankel matrix completion through nonconvex optimization.” IEEE Journal of Selected Topics in Signal Processing (JSTSP), no. 4: 617-632. IEEE, 2018. [pdf]